attention图解
回顾自注意力机制
语言离不开语境,比如这个第二定律:
机器人第二定律
机器人必须服从人给予它的命令,当命令与第一定律冲突时例外。
笔者已强调了句子中有三处单词与其他单词有联系。如果不结合语境是无法理解或者处理单词的,所以在模型处理这句话时,了解语境是必要的:
· 这句话是讲机器人的
· 这样的命令是定律早期的一部分,也即“人类发出的指令”
· 第一定律就是指整个第一定律
自注意力层的流程就是这样。如同烘培一样,它会在加工特定文字之前对其关联词进行预处理(再传递给神经网络层)。其方式就是对每个单词在语段中的相关度进行评分,然后把结果向量加起来。
例如,顶部的transformer模块的自注意力层在处理“it”时,将重点放在了“robot”上。那么传递给神经网络层的向量将是三个单词中每个单词的向量乘以其分数的总和。

自注意力机制处理
自注意力机制会贯穿于语段中每个词的处理路径。其中重要的组件是三个向量:
· Query(查询):展示了当前的单词,该单词会使用键给其他单词评分。我们只需要注意目前正在处理的词的查询。
· Key(键):键向量就像段中所有单词的标签,是搜索相关词汇时的匹配项。
· Value(值):值向量是实际单词的体现,给每个单词的相关度评过分后,加起来的值就会用来表示当前的单词。
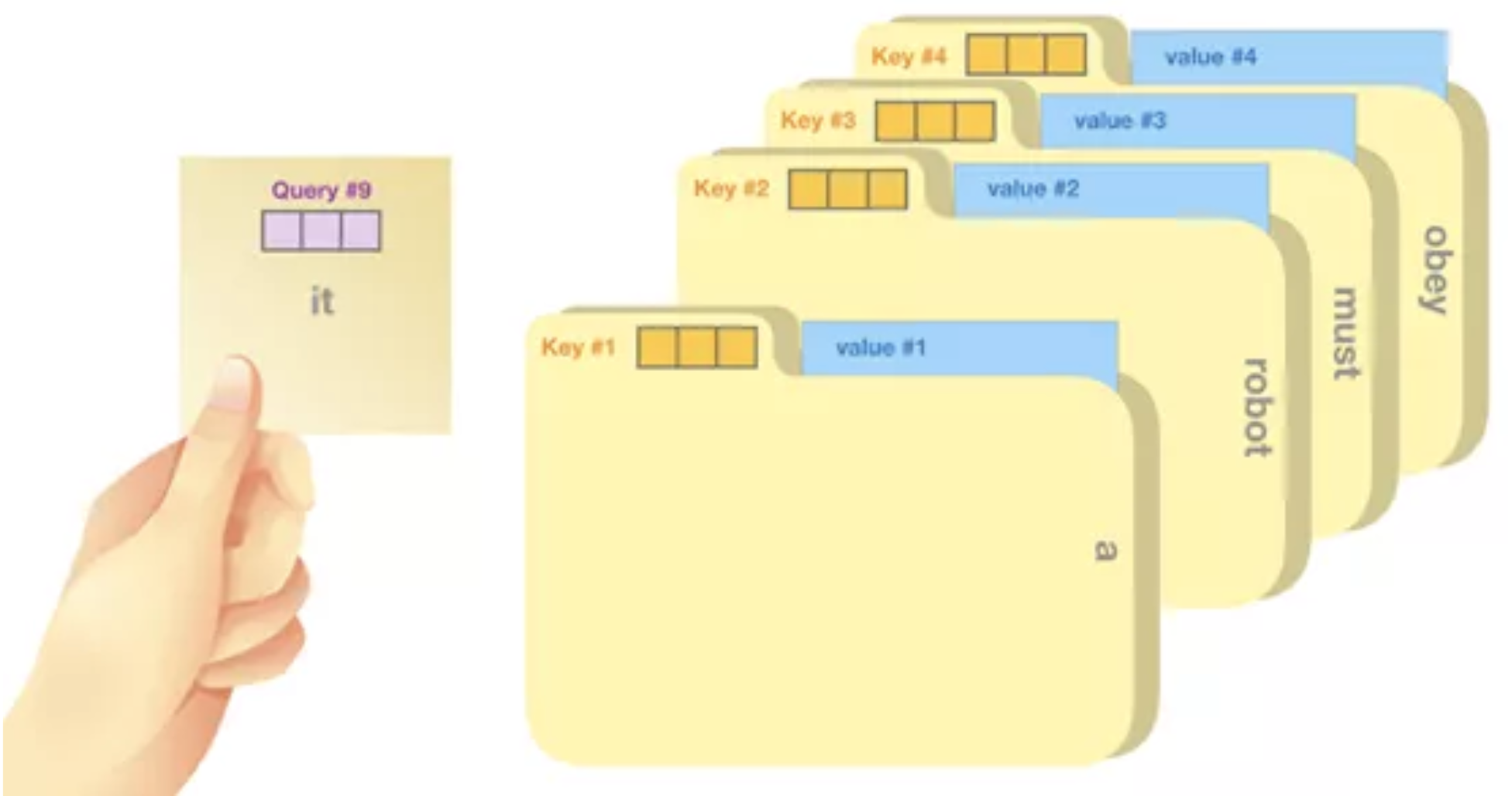
该过程可大致理解为在文件柜里进行搜索。查询就如同写有搜索主题的便利贴,键是里面的文件夹名称。对着便利贴寻找标签时,会提取文件夹中的内容,这些内容就是值向量。如果所找值不是一个,而是无数文件夹中的各个值,就要另当别论了。
将查询向量乘以每个键向量,得到的值即为每个文件夹对应的分数(从专业角度讲:乘指的是向量点乘,乘积会通过 softmax 函数处理)。
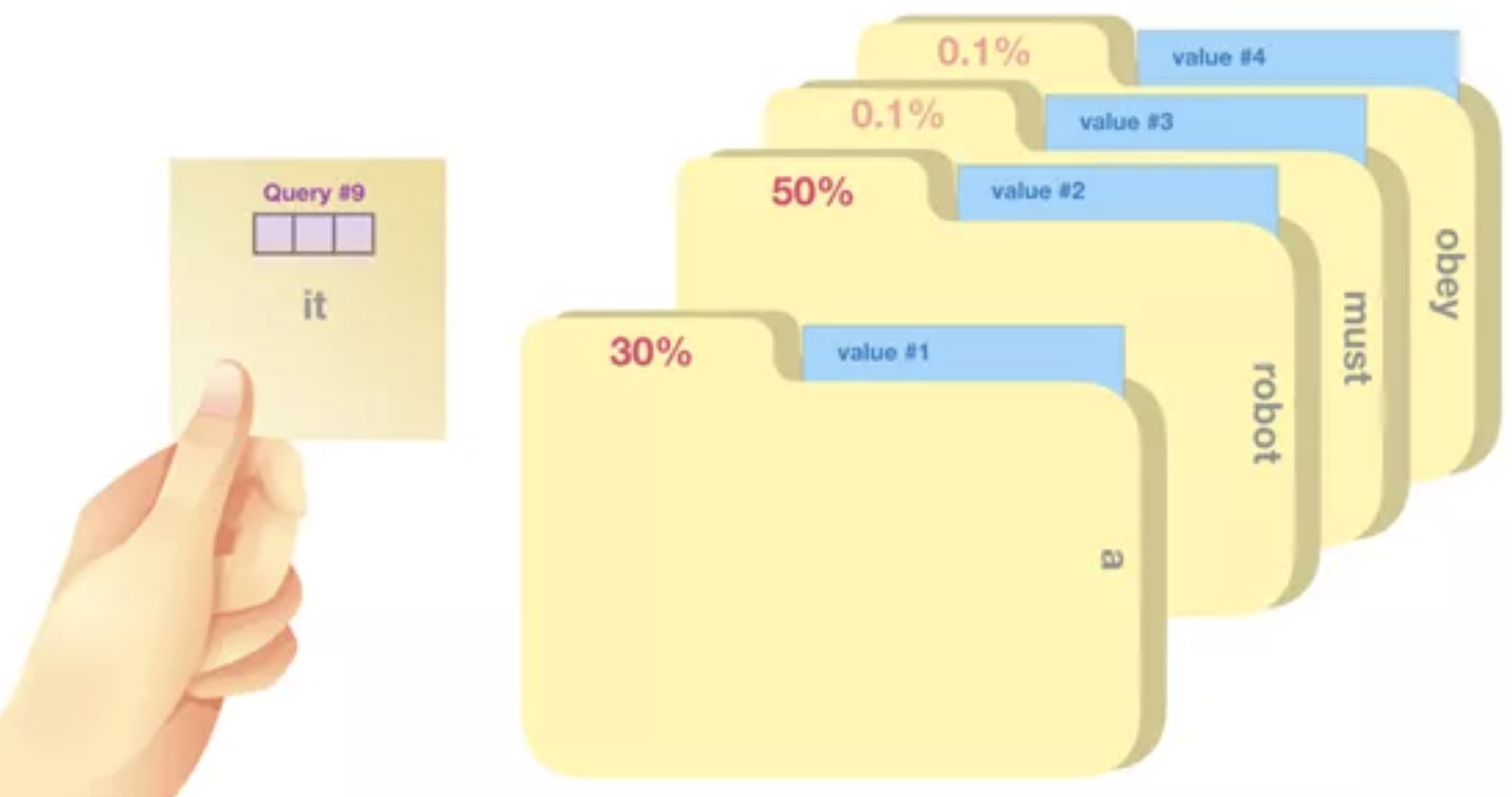
将值与其分数相乘,再求总和——得出自注意力层结果。
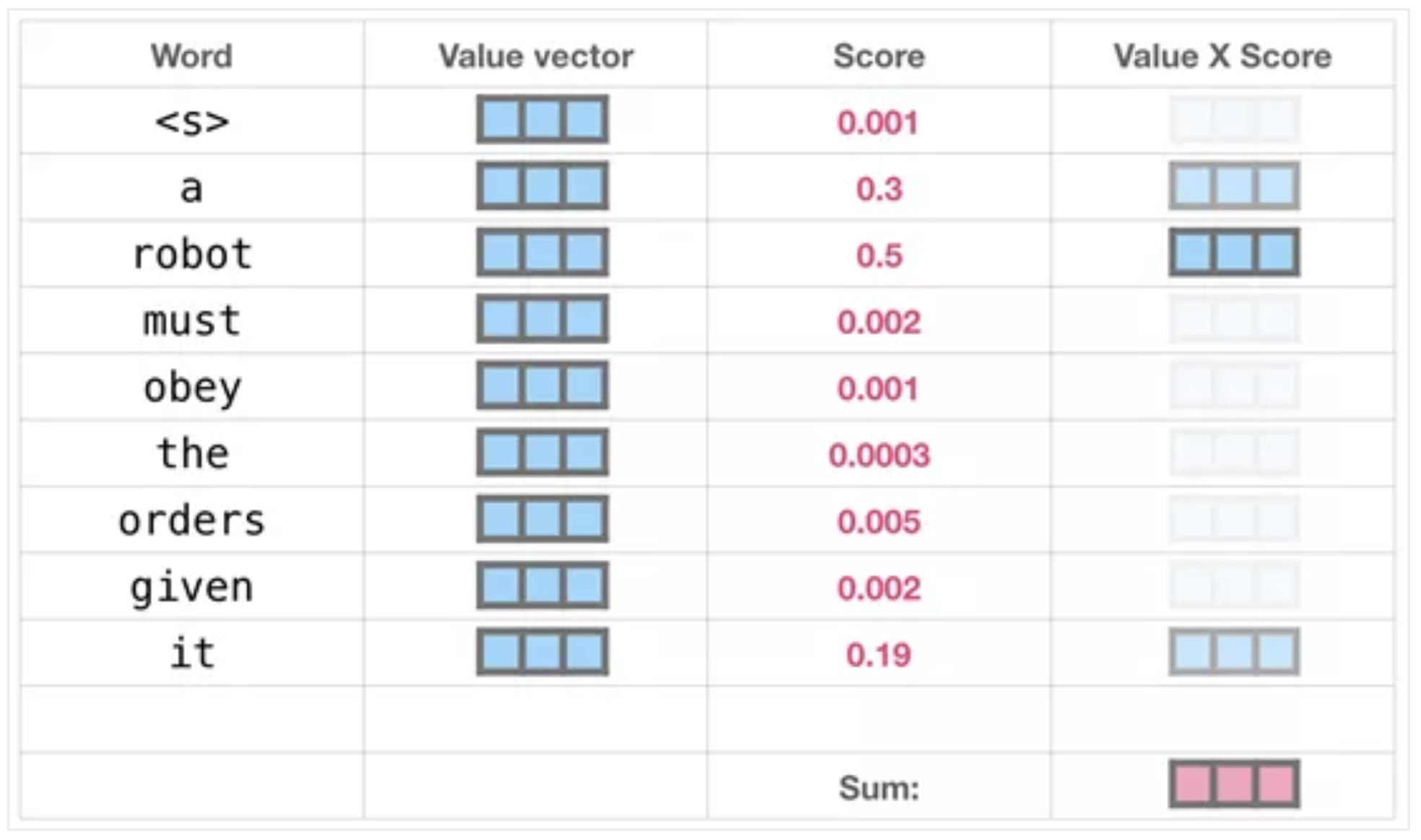
该加权向量值的结果,会让模型将50%的注意力都放在词语“robot”上,30%的注意力放在“a”上,还有19%会在“it”上。