linux常用命令
处理数据常用的命令,包括 sort、awk、cut 等常用命令(持续 ing)
进程
ps -f命令也能够表现子shell的嵌套关系
时间
date
-d<字符串>:显示字符串所指的日期与时间。字符串前后必须加上双引号;
-s<字符串>:根据字符串来设置日期与时间。字符串前后必须加上双引号;
date [选项]... [+格式]
或:date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]]
Display the current time in the given FORMAT, or set the system date.
Mandatory arguments to long options are mandatory for short options too.
-d, --date=STRING 显示由STRING 描述指定的时间, 不是默认的'now'
-f, --file=DATEFILE like --date once for each line of DATEFILE
-I[TIMESPEC], --iso-8601[=TIMESPEC] 使用ISO 8601格式显示 date/time
TIMESPEC可以设置为'date', 'hours', 'minutes', 'seconds', 'ns'
来指定显示的精度,默认是date
-r, --reference=文件 显示指定文件的最后修改时间
-R, --rfc-2822 以RFC 2822格式输出日期和时间
例如:2006年8月7日,星期一 12:34:56 -0600
--rfc-3339=TIMESPEC output date and time in RFC 3339 format.
TIMESPEC='date', 'seconds', or 'ns' for
date and time to the indicated precision.
Date and time components are separated by
a single space: 2006-08-07 12:34:56-06:00
-s, --set=STRING 用描述时间的字符串 STRING 设置时间
-u, --utc, --universal 显示或设置 Coordinated Universal Time
--help 显示此帮助信息并退出
--version 显示版本信息并退出
格式化参数
给定的格式FORMAT 控制着输出,解释序列如下:
%% 一个%
%a 当前locale 的星期名缩写(例如: 日,代表星期日)
%A 当前locale 的星期名全称 (如:星期日)
%b 当前locale 的月名缩写 (如:一,代表一月)
%B 当前locale 的月名全称 (如:一月)
%c 当前locale 的日期和时间 (如:2005年3月3日 星期四 23:05:25)
%C 世纪;比如 %Y,通常为省略当前年份的后两位数字(例如:20)
%d 按月计的日期(例如:01)
%D 按月计的日期;等于%m/%d/%y
%e 按月计的日期,添加空格,等于%_d
%F 完整日期格式,等价于 %Y-%m-%d
%g ISO-8601 格式年份的最后两位 (参见%G)
%G ISO-8601 格式年份 (参见%V),一般只和 %V 结合使用
%h 等于%b
%H 小时(00-23)
%I 小时(00-12)
%j 按年计的日期(001-366)
%k hour, space padded ( 0..23); same as %_H
%l hour, space padded ( 1..12); same as %_I
%m month (01..12)
%M minute (00..59)
%n 换行
%N 纳秒(000000000-999999999)
%p 当前locale 下的"上午"或者"下午",未知时输出为空
%P 与%p 类似,但是输出小写字母
%r 当前locale 下的 12 小时时钟时间 (如:11:11:04 下午)
%R 24 小时时间的时和分,等价于 %H:%M
%s 自UTC 时间 1970-01-01 00:00:00 以来所经过的秒数
%S 秒(00-60)
%t 输出制表符 Tab
%T 时间,等于%H:%M:%S
%u 星期,1 代表星期一
%U 一年中的第几周,以周日为每星期第一天(00-53)
%V ISO-8601 格式规范下的一年中第几周,以周一为每星期第一天(01-53)
%w 一星期中的第几日(0-6),0 代表周一
%W 一年中的第几周,以周一为每星期第一天(00-53)
%x 当前locale 下的日期描述 (如:12/31/99)
%X 当前locale 下的时间描述 (如:23:13:48)
%y 年份最后两位数位 (00-99)
%Y 年份
%z +hhmm 数字时区(例如,-0400)
%:z +hh:mm 数字时区(例如,-04:00)
%::z +hh:mm:ss 数字时区(例如,-04:00:00)
%:::z 数字时区带有必要的精度 (例如,-04,+05:30)
%Z 按字母表排序的时区缩写 (例如,EDT)
默认情况下,日期的数字区域以0填充。
%后面可以加 下面这些标记:
- (hyphen) do not pad the field
_ (underscore) pad with spaces
0 (zero) pad with zeros
^ use upper case if possible
# use opposite case if possible
在任何标记之后还允许一个可选的域宽度指定,它是一个十进制数字。
作为一个可选的修饰声明,它可以是E,在可能的情况下使用本地环境关联的
表示方式;或者是O,在可能的情况下使用本地环境关联的数字符号。
例子:
Convert seconds since the epoch (1970-01-01 UTC) to a date
$ date --date='@2147483647'
Show the time on the west coast of the US (use tzselect(1) to find TZ)
$ TZ='America/Los_Angeles' date
Show the local time for 9AM next Friday on the west coast of the US
$ date --date='TZ="America/Los_Angeles" 09:00 next Fri'
格式化
date +"%Y-%m-%d"
时间游走
1.加减操作
date +%Y%m%d //显示前天年月日
date -d "+1 day" +%Y%m%d //显示前一天的日期
date -d "-1 day" +%Y%m%d //显示后一天的日期
date -d "-1 month" +%Y%m%d //显示上一月的日期
date -d "+1 month" +%Y%m%d //显示下一月的日期
date -d "-1 year" +%Y%m%d //显示前一年的日期
date -d "+1 year" +%Y%m%d //显示下一年的日期
2.文字版本
date -d "1 day ago" +"%Y-%m-%d %H:%M:%S" # 一天前
date -d "1 day" +"%Y-%m-%d %H:%M:%S" # 一天后
date -d "2009-12-12 1 year ago" +"%Y/%m/%d %H:%M.%S" # 指定时间的一年前
date -d "2009-12-12 1 year" +"%Y/%m/%d %H:%M.%S" # 指定时间的一年后
设置时间
date -s //设置当前时间,只有root权限才能设置,其他只能查看
date -s 20120523 //设置成20120523,这样会把具体时间设置成空00:00:00
date -s 01:01:01 //设置具体时间,不会对日期做更改
date -s "01:01:01 2012-05-23" //这样可以设置全部时间
文本处理
echo
-e:输出转义字符
-n:不换行输出
RCol='\e[0m' # Text Reset
# Regular Bold Underline High Intensity BoldHigh Intens Background High Intensity Backgrounds
Bla='\e[0;30m'; BBla='\e[1;30m'; UBla='\e[4;30m'; IBla='\e[0;90m'; BIBla='\e[1;90m'; On_Bla='\e[40m'; On_IBla='\e[0;100m';
Red='\e[0;31m'; BRed='\e[1;31m'; URed='\e[4;31m'; IRed='\e[0;91m'; BIRed='\e[1;91m'; On_Red='\e[41m'; On_IRed='\e[0;101m';
Gre='\e[0;32m'; BGre='\e[1;32m'; UGre='\e[4;32m'; IGre='\e[0;92m'; BIGre='\e[1;92m'; On_Gre='\e[42m'; On_IGre='\e[0;102m';
Yel='\e[0;33m'; BYel='\e[1;33m'; UYel='\e[4;33m'; IYel='\e[0;93m'; BIYel='\e[1;93m'; On_Yel='\e[43m'; On_IYel='\e[0;103m';
Blu='\e[0;34m'; BBlu='\e[1;34m'; UBlu='\e[4;34m'; IBlu='\e[0;94m'; BIBlu='\e[1;94m'; On_Blu='\e[44m'; On_IBlu='\e[0;104m';
Pur='\e[0;35m'; BPur='\e[1;35m'; UPur='\e[4;35m'; IPur='\e[0;95m'; BIPur='\e[1;95m'; On_Pur='\e[45m'; On_IPur='\e[0;105m';
Cya='\e[0;36m'; BCya='\e[1;36m'; UCya='\e[4;36m'; ICya='\e[0;96m'; BICya='\e[1;96m'; On_Cya='\e[46m'; On_ICya='\e[0;106m';
Whi='\e[0;37m'; BWhi='\e[1;37m'; UWhi='\e[4;37m'; IWhi='\e[0;97m'; BIWhi='\e[1;97m'; On_Whi='\e[47m'; On_IWhi='\e[0;107m';
cat
cat -A test 显示隐藏字符如^A,^B
cat -n test 所有的行加上行号
cat -b test 【有文本的行】 加上行号,【空白行】不算
cat -T test 以^I显示制表符
tail
tail -n 2 -f log_file
-f 参数是 tail 命令的一个突出特性。它允许你在其他进程使用该文件时查看文件的内容。tail命令会保持活动状态,并不断显示添加到文件中的内容。这是实时监测系统日志的绝妙方式。
uniq
uniq命令用于报告或忽略文件中的重复行,查重复行的时候,只会检查相邻的行,因此一般与sort命令结合使用,让重复的排在一起。比如下面:aa 统计结果是出现了 2 次,后面又有出现 1 次的 aa
# 文本
aa
aa
c
aa
# uniq 后
uniq -c
2 aa
1 c
1 aa
常用参数:
-c或——count: 在每列旁边显示该行重复出现的次数;
-u或——unique: 仅显示出一次的行列;
-d或--repeated: 仅输出重复出现的行列,且重复的只输出一行;
-D, --all-repeated 仅输出重复的行,有几行输出几行
-i, --ignore-case 不区分大小写
-w<字符位置>或--check-chars=<字符位置> 指定要比较的前 n 个字符,忽略后面的内容
-f<栏位>或--skip-fields=<栏位> 忽略前n列(空格分割),-f 1 忽略第一列
-s<字符位置>或--skip-chars=<字符位置> 忽略前n个字符 -s 4 忽略前 4 个字符
-z 忽略换行(不知道有什么用)
提供的测试文件
this is a test
this is a test
this is a test
i am tank
i love tank
i love tank
this is a test
whom have a try
WhoM have a try
WhoM have a try1
you have a try
i want to abroad
those are good men
we are good men
参考:http://blog.51yip.com/shell/1022.html
两个文件的交并集
如果你知道怎么用sort/uniq来做集合交集、并集、差集能很大地促进你的工作效率。假设有两个文本文件a和b已经被uniq了,那么,用sort/uniq会是最快的方式,无论这两个文件有多大(sort不会被内存所限,你甚至可以使用-T选项,如果你的/tmp目录很小)
cat a b | sort | uniq > c # c is a union b 并集
cat a b | sort | uniq -d > c # c is a intersect b 交集
cat a b b | sort | uniq -u > c # c is set difference a - b 差集
sort
全局选项
| 选项 | 解释 | ||||
|---|---|---|---|---|---|
| -b | –ignore-leading-blanks | 排序时忽略起始的空白,空格数量不固定时,该选项几乎是必须要使用的。”-n”选项隐含该选项。 | |||
| -c | –check | 仅检查输入数据是不是已排序;未排序的话,会输出诊断信息,提示从哪一行开始乱序。 | |||
| -t | –field-separator=SEP | 指定分隔符,如果是\t,需要这样sort -t$'\t' file。默认的分隔符为空白字符和非空白字符之间的空字符,并非网上众多文章所说的空格或制表符(By default, fields are separated by the empty string between a non-blank character and a blank character)。” foo bar”被分割为:` |
foo | bar( |
`视为分割符) |
| -u | –unique | 在输出行中去除重复行,只识别用-k设定的域,发现都相同的才会删除,只要其中有一级不同都不会轻易删除的。 |
|||
| -n | –numeric-sort | 指定-n使用数值比较,默认是字符串比较,一遇到不可识别字符就会立即结束该字段的排序行为,无法跨域使用。”n”选项隐含”b”选项。 | |||
| -g | –general-number-sort | 按通用数值来排序(跟-n不同,把值当浮点数来排序,支持科学 计数法表示的值) | |||
| -r | –reverse | 默认从小到大,指定后改为从大到小排序 | |||
| -f | –ignore-case | 忽略大小写,未指定情况下,会将大写字母排在前面;在和”-u”选项一起使用时,如果排序字段的比较结果相等,则丢弃小写字母行。 | |||
| -o | –output=file | 排序结果输出到指定文件,对于保存到原文件很有用,不然是可以用重定向的 | |||
| -m | –merge | 对给定的多个已排序文件进行合并。在合并过程中不做任何排序动作。 | |||
| -k | –key=POS1[,POS2] | 指定排序的列,排序从POS1位置开始;如果指定了POS2的话, 到POS2位置结 束 | |||
| -s | –stable | 禁用”最终排序”。推荐大文件使用,能确认要排序的列后,不启用可以提高性能 | |||
| -z | –zero-terminated | NULL字符作为行尾,而不是用换行符 | |||
| –debug | 查看排序的过程和排序时所使用的列。注意,该选项只有CentOS 7上的sort才有。 |
知识点
私有选项:紧跟在字段后的选项(如”-k3n”的”n”和”-k2r”的”r”)称为私有选项,使用短横线写在字段外的选项(如”-n”、”-r”)为全局选项。当没有为字段分配私有选项时,该排序字段将继承全局选项。当然,只有像”-n”、”-r”这样的排序性的选项才能继承和分配给字段,”-t”这样的选项则无法分配。
除了”b”选项外,其余选项无论是指定在POS1还是POS2中都是等价的,对于”b”选项,指定在POS1则作用于POS1,指定在POS2则作用于POS2。如果继承了全局选项”-b”,则作用于POS1和POS2。
因此,”-n -k3 -k4”、”-n -k3n -k4”和”-k3n -k4n”是等价的,”-r -k3n -k4”和”-k3nr -k4r”是等价的
排序规则:sort命令默认按照字符集的排序规则进行排序,可以指定”-d”选项按照字典顺序排序,指定”-n”按照数值排序,指定”-M”按照字符格式的月份规则排序,指定”-h”按照文件容量大小规则排序。
分隔符 :sort使用-t选项指定的分隔符对每行进行分割,得到多个字段,分隔符不作为字段的内容,跨域时也没有,注意-n无法跨域,会造成分隔符在其中的错觉。默认的分隔符为空白字符和非空白字符之间的空字符,并非网上众多文章所说的空格或制表符(原文:By default, fields are separated by the empty string between a non-blank character and a blank character.)。
“ foo bar”默认将分隔为两个字段” foo”和” bar”,空格都保留着,可以视为”| foo| bar”,|为分割符。而使用空格作为分隔符时将分隔为三个字段:第一个字段为空,第二个字段和第三个字段为”foo”和”bar”。使用下面三个sort语句可以验证默认的分隔符并非空格。
$ echo -e " 234 bar\n 323 aar" | sort -k2 # 视为 2 列,对(aar,bar)排序 323 aar 234 bar $ echo -e " 234 bar\n 323 aar" | sort -t' ' -k2 # 视为 3 列,对 (234,323)排序 234 bar 323 aar $ echo -e " 234 bar\n 323 aar" | sort -b -t' ' -k1 # 视为 2 列,因为全局选项-b 去除了开头的空格 123 aar 234 bar $ echo -e " 234 bar\n 323 aar" | sort -t' ' -bk3 # 视为 3 列,对(aar, bar)排序,私有选项忽略 bar 前的空格 323 aar 234 bar
分割后字段:分割字段后,分隔符不在排序目标中,跨域时也不包括(-n无法跨域,会造成分隔符在其中的错觉),分割后两个字段A和B是紧靠在一起的。当排序的目标字段包含了B字段,那么sort会从字段左对齐处开始依次对字符排序。
[root@xuexi ~]# cat sort.txt
11:1:2
1:1:2
12:1:1
1:1:0
[root@xuexi ~]# sort -t: sort.txt
1:1:0
11:1:2
1:1:2
12:1:1
上面排序例子中,为什么”1:1:2”的1会在11和12中间,而”1:1:0”中的1却在11的前面?实际上,真正排序的时候,sort看到的内容是这样的:
1112
112
1211
110
注意:info sort 文档中说跨域时分隔符会保留感觉是错的。通过下面的例子进行测试
$ cat t
a ae
aa da
$ sort -t" " -k1,2 t # d > e
aa da
a ae
最后排序:默认情况下,在命令行中指定的排序行为结束后,sort还会做最后一次排序,这最后一次排序是对整行按照完全默认规则进行排序的,也就是按字符集、升序排序。
考虑这样一种情况:两行在所有key的排序结果上都完全相同,应该如何决定这两行的先后顺序?
例如:
[root@xuexi ~]# echo -e "b 100 200\na 100 300" | sort -t ' ' -k2n
a 100 300
b 100 200
第一行为”b 100 200”,第二行为”a 100 300”。由于第2字段都是100,所以这两行在该key上的数值排序的结果相同,于是sort采取最后的手段,完全按照默认规则(即按字符集排序规则升序排序)对整行进行一次排序,这次排序称为”最后的排序”(info sort中称为last-resort comparison)。由于最后的排序过程中,第一个字符a<b,所以最终结果将是第二行”a 100 300”在第一行”b 100 200”的前面。
禁止”最后的排序”后,对那些排序key相同的行,将保留被读取时相对顺序。即,先读取的排在前面。
如果上面的例子中,第二字段不采用数值排序,而是默认排序规则排序呢?如下:
[root@xuexi ~]# echo -e "b 100 200\na 100 300" | sort -t ' ' -k2
b 100 200
a 100 300
由于默认的排序规则是按照字符集排序规则进行排序,它能识别所有的字符,所以-k2等价于-k2,3,对整个key进行排序,由于第三字段的2小于3,所以结果中第一行排在第二行的前面。即使如此,sort还是进行了”最后的排序”,只不过”最后的排序”不影响排序结果。
如果未指定任何排序选项,其本身就是完全默认的,因此没必要再做最后的排序,所以将不会进行”最后的排序”。如果指定的是”-r”选项,由于”-r”是对最终结果进行反转排序,因此会影响这次的”最后的排序”的结果。
排序对象
使用”-k”选项指定排序的key。不指定排序key时,整行将成为排序key,即对整行进行排序。
- key由字段组成,格式为
POS1,[POS2],表示每行排序的起始和终止位置。也就是说,key才是排序的对象。 - POS的格式为
F[.C][OPTS],其中F表示字段的序号,C表示该字段中字符的序号。字段和字符的位置都从1开始计算。如果POS2的字符位置指定为0,则表示POS2字段中的最后一个字符。如果POS1中省略.C,则默认值为1(字段的起始字符),如果POS2中省略.C,默认值为0(字段的终止字符)。使用”-b”选项忽略前导空白字符时,C从第一个非空白字符开始计算。如果F或C超出了有效范围,则该key为空,例如一行只有3个字段,却指定了”-k4”,或者第2字段只有3个字符,却指定了”-k2.5”。 - 如果省略POS2,则key将自动扩展到行尾,即等价于”POS1,line_end”。如果不省略POS2,则该key可能会跨越多个字段。无论那种情况,跨越多个字段时,key中都不会保留字段间的分隔符。
- OPTS指定的是该key的选项,包括但不限于
bfnrhM,它们的作用和全局选项”-b”、”-f”、”-n”、”-r”、”-h”、”-M”相同。默认情况下,如果key中没有指定任何OPTS,则该key会继承全局选项。当key中单独指定了选项时,这些选项是该key的私有排序选项,将覆盖全局选项。除了”b”选项外,其余选项无论是指定在POS1还是POS2中都是等价的,对于”b”选项,指定在POS1则作用于POS1,指定在POS2则作用于POS2。如果继承了全局选项”-b”,则作用于POS1和POS2。-n选项无法跨域。 - 字段前数量不固定的前导空白字符,将使得字段混乱,因此强烈建议总是忽略前导空白字符。数值排序时(即”n”选项)隐含”b”选项。
- 可以使用多个”-k”选项指定多个key,排序时将按照key的顺序进行排序。第一个key通常称为主排序key(primary key)。第二个key将在第一个key排序的基础上排序,同理,第三个key将在第二个key的排序基础上进行排序。
以下是几个例子:例子中出现了选项”n”的,描述暂不严谨,但目前只能如此描述,在稍后的(4)中解释。
-k 2: 因为没有指定POS2,所以key扩展到了行尾。因此该key从第2字段第一个字符开始,到行尾结束。-k 2,3:该key从第2字段第一个字符开始到第3字段最后一个字符结束。-k 2,2: 该key仅拥有第2字段。-k 2,3n和-k 2n,3和-k 2n,3n:这三者等价,因为除了”b”选项,OPTS指定在POS1或POS2的结果是一样的。-k 2,3b和-k 2b,3和-k 2b,3b:这三者互不等价。-k 2n: 该key从第2字段开始直到行尾,都按数值排序。-k 2.2b,3.2n: 该key从第2字段的第2个非空白字符开始,到第3字段第2字符(可能包含空白字符)结束,且该key按照数值排序。其实此处的b选项是多余的,因为n隐含了b选项。-k 5b,5 -k 3,3n: 定义了两个排序key,主排序key为第5字段不包含空白字符的部分,副key为第三个字段。主key按照默认规则排序,副key按照数值排序。副key在主key排序后的基础上再排序。-k 5,5n -k 3b,6b: 主key为第5字段,按照数值排序,副key从第3字段到第六字段,忽略前导空白字符,但是按照默认规则排序。副key在主key排序后的基础上再排序。
建议
- 任何时候想对单个字段或单个字符排序时,都建议写出POS2,且POS2=POS1,这样能严格排序key的范围只为那个字段或字符。例如,使用
-k2,2取代-k2。 - 想对多个字段或字符排序时,建议使用多个”-k”选项指定多个key,并按需求为每个key分配私有选项。之所以要如此,是防止无意中忽视了扩展到行尾或者范围。例如,想对第2列、第3列按数值排序,应该指定
-k2n -k3n,而不应该写成-k2,3n。 - 应该总是使用
-b选项去掉前导空白字符面,防止字段分割时混乱。-n隐含了-b,所以对数值排序时,可以省略-b。 - 对于大文件,建议写出满足需求的所有排序命令,然后使用
-s关闭”最后的排序”。因为”最后的排序”对每个整行进行排序,性能非常低。
多列排序
sort按照某列排序,一样的话再按某一列排序
sort -k2,2 -k5,5 wide_table |grep "DD4486F320A7F0C112E2757C26609769"
例子
从公司英文名称的第二个字母开始进行排序:
$ sort -t ' ' -k 1.2 facebook.txt baidu 100 5000 sohu 100 4500 google 110 5000 guge 50 3000使用了
-k 1.2,表示对第一个域的第二个字符开始到本域的最后一个字符为止的字符串进行排序。按照员工工资降序排序,如果员工人数相同的,则按照公司人数升序排序
$ sort -n -t ' ' -k 3r -k 2 facebook.txt baidu 100 5000 google 110 5000 sohu 100 4500 guge 50 3000在-k 3后面偷偷加上了一个小写字母r。r和-r选项的作用是一样的,就是表示逆序,不过只对当前域有效,表示第三个域(员工平均工资)是按照降序排序。此处你还可以加上n,就表示对这个域进行排序时,要按照数值大小进行排序
$ sort -t ' ' -k 3nr -k 2n facebook.txt baidu 100 5000 google 110 5000 sohu 100 4500 guge 50 3000我们去掉了最前面的-n选项,而是将它加入到了每一个-k选项中了。
只针对公司英文名称的第二个字母进行排序,如果相同的按照员工工资进行降序排序
$ sort -t ' ' -k 1.2,1.2 -k 3nr facebook.txt baidu 100 5000 google 110 5000 sohu 100 4500 guge 50 3000我们使用了-k 1.2,1.2的表示方式,表示我们“只”对第二个字母进行排序。(如果你问“我使用-k 1.2怎么不行?”,当然不行,因为你省略了End部分,这就意味着你将对从第二个字母起到本域最后一个字符为止的字符串进行排序)。
最诡异的排序(跨域是不行的)
$ sort -n -k 2.2,3.1 facebook.txt guge 50 3000 baidu 100 5000 sohu 100 4500 google 110 5000以第二个域的第二个字符开始到第三个域的第一个字符结束的部分进行排序。
第一行,会提取0 3,第二行提取00 5,第三行提取00 4,第四行提取10 5。
又因为sort认为0小于00小于000小于0000….
因此0 3肯定是在第一个。10 5肯定是在最后一个。但为什么00 5却在00 4前面呢?(你可以自己做实验思考一下。)
答案揭晓:原来“跨域的设定是个假象”,sort只会比较第二个域的第二个字符到第二个域的最后一个字符的部分,而不会把第三个域的开头字符纳入比较范围。当发现00和00相同时,sort就会自动比较第一个域去了。当然baidu在sohu前面了。
http://blog.chinaunix.net/uid-10540984-id-313479.html
https://www.cnblogs.com/f-ck-need-u/p/7442886.html
find
find [-H] [-L] [-P] [-Olevel] [-D help|tree|search|stat|rates|opt|exec] [path...] [expression]
任何位于表达式(expression)之前的字符串都将被视为欲查找的目录名。
默认路径为当前目录;默认表达式为-print
表达式(expression)可能由下列成份组成:操作符、选项、测试表达式以及动作:
find会对每个文件评估从左向右的表达式,直到结果明确为真 或 表达式全部执行结束。
-H,-L和-P选项控制符号链接的处理。后面的命令行参数被视为要检查的文件或目录的名称,直到开始的第一个参数使用’ - ‘或参数’(’或’!’。该参数和任何后续参数被视为描述要搜索内容的表达式。
五个’真正的’选项-H,-L,-P, -D和-O必须出现在第一个路径名之前
操作符 (优先级递减;未做任何指定时默认使用 -and):
( EXPR )
! EXPR
-not EXPR
EXPR1 -a EXPR2
EXPR1 -and EXPR2
EXPR1 -o EXPR2
EXPR1 -or EXPR2
EXPR1 , EXPR2
位置选项 (总是真):
-daystart # 从本日开始计算时间;TODO
-follow 废弃; 使用-L代替, 排除符号连接;
-regextype 普通选项 (总是真,在其它表达式前指定):
-depth # 从指定目录下最深层的子目录开始查找,不像默认的一层一层目录往下找,如下:
# ./logs/hadoop.kylin.libdfs.log
# ./logs
-maxdepth LEVELS # 设置最大目录层级;
-mindepth LEVELS # 搜索深度距离当前目录至少2个子目录的所有文件
-mount # 此参数的效果和指定“-xdev”相同;
-xdev # Don’t descend directories on other filesystems.TODO
-ignore_readdir_race
-noignore_readdir_race
--version
--help
比较测试 (N 可以是 +N 或 -N 或 N):
+N for greater than N,
-N for less than N,
N for exactly N.
-amin N # 查找在指定时间曾被存取过的文件或目录,单位以分钟计算;
-mmin N # 查找在指定时间曾被更改过的文件或目录,单位以分钟计算;
-cmin N # 查找在指定时间之时被更改过的文件或目录,单位以分钟计算;
-atime N # 查找在指定时间曾被存取过的文件或目录,单位以24小时计算;
-mtime N # 查找在指定时间曾被更改过的文件或目录,单位以24小时计算;
-ctime N # 查找在指定时间之时被更改的文件或目录,单位以24小时计算;
-cnewer 文件 # 查找其更改时间较指定文件或目录的更改时间更接近现在的文件或目录;
-anewer 文件 # 查找其存取时间较指定文件或目录的存取时间更接近现在的文件或目录;
-empty
-true # 将find指令的回传值皆设为True;
-false # 将find指令的回传值皆设为False;
-fstype 类型 # 只寻找该文件系统类型下的文件或目录;
-gid N # 查找符合指定之群组识别码的文件或目录;
-group 名称 # 查找符合指定之群组名称的文件或目录;
-uid N # 查找符合用户uid的文件或目录
-user NAME # 查找符和指定的拥有者名称的文件或目录
# 匹配模式使用的是shell的通配符(除了regex)
-name 匹配模式 # *.py 最好配合*使用,精确指定可能得不到想要的结果
-regex 匹配模式 # 需要较多的转义,请看后面的例子
-path 匹配模式 # 与name很像,必须配合*使用,指定字符串作为寻找目录的范本样式,只要目录中包含匹配的模式,就输出
-perm [+-]访问模式 # 查找符合指定的权限数值的文件或目录;
-lname 匹配模式 # 查找是符号链接的文件,并且其内容匹配模式
-newer 文件或目录 # 查找其更改时间较指定文件或目录的更改时间更接近现在的文件或目录;
# 忽略字符大小写的差别
-iname 匹配模式 -ipath 匹配模式 -iregex 匹配模式 -ilname 匹配模式
-links N # 查找符合指定的硬连接数目的文件或目录;
-inum N # 查找符合指定的inode编号的文件或目录;
-nouser -nogroup # 找出不属于本地主机[用户识别码/群组识别码]的文件或目录;
-noleaf # 不去考虑目录至少需拥有两个硬连接存在;
# 可读写执行
-readable -writable -executable
-wholename PATTERN # TODO
-size N[bcwkMG] # 查找符合指定的文件大小的文件;
-type [bcdpflsD] # 只寻找符合指定的文件类型的文件;
-used N # 查找文件或目录被更改之后在指定时间曾被存取过的文件或目录,单位以日计算;
-xtype [bcdpfls] # 和指定“-type”参数类似,差别在于它针对符号连接检查。
动作: -delete
-print # 若回传值为Ture,就将符合的文件或目录名称列出到标准输出。格式为每列一个名称,每个名称前皆有“./”字符串;
-print0 # 回传值为Ture,就将符合的文件或目录名称列出到标准输出。格式为全部的名称皆在同一行;
-printf FORMAT # 回传值为Ture,就将文件或目录名称列出到标准输出。格式可以自行指定;
-fprintf FILE FORMAT # 此参数的效果和指定“-printf”参数类似,但会把结果保存成指定的列表文件;
-fprint0 FILE # 指定“-print0”参数类似,但会把结果保存成指定的列表文件;
-fprint FILE # 和指定“-print”参数类似,但会把结果保存成指定的列表文件;
-ls # 对符合条件的文件或目录执行ll命令,显示详细信息
-fls FILE # 和指定“-ls”参数类似,但会把结果保存为指定的列表文件;
-prune # 不打印符合条的文件或目录
-quit
# 执行的命令不支持你自定义的alias
-exec COMMAND {} \; # find指令的回传值为True,就执行该指令;
-ok COMMAND {} \; # 与-exec相似,但是会给出提示,是否执行相应的操作。
-exec COMMAND {} + -ok COMMAND ; # {}是一个占位符,用于与-exec选项结合使用来匹配所有文件,然后会被替换为相应的文件名
-execdir COMMAND ;
-execdir COMMAND {} + -okdir COMMAND ;
在/home目录下查找以.txt结尾的文件名
find /home -name "*.txt"
当前目录及子目录下查找所有以.txt和.pdf结尾的文件
find . -name "*.txt" -o -name "*.pdf"
匹配文件路径或者文件
find /usr/ -path "*local*"
name与path的区别
$ find . -ipath "*match*"
./bin/match
./bin/match/match.py
./data/match_result.txt
./data/match
./data/match/20190910 # 这一行的差别
./data/match/20190910/match_result_20190910.txt
./data/match_result_20190910.txt
$ find . -iname "*match*"
./bin/match
./bin/match/match.py
./data/match_result.txt
./data/match
./data/match/20190910/match_result_20190910.txt
./data/match_result_20190910.txt
基于正则表达式匹配文件路径
find . -regex ".*\(\.txt\|\.pdf\)$"
否定参数
找出/home下不是以.txt结尾的文件
find /home ! -name "*.txt"
类型参数列表:
- f 普通文件
- l 符号连接
- d 目录
- c 字符设备
- b 块设备
- s 套接字
- p Fifo
UNIX/Linux文件系统每个文件都有三种时间戳:
- 访问时间(-atime/天,-amin/分钟):用户最近一次访问时间。
- 修改时间(-mtime/天,-mmin/分钟):文件最后一次修改时间。
- 变化时间(-ctime/天,-cmin/分钟):文件数据元(例如权限等)最后一次修改时间。
搜索最近七天内被访问过的所有文件
find . -type f -atime -7
搜索恰好在七天前被访问过的所有文件
find . -type f -atime 7
搜索超过七天内被访问过的所有文件
find . -type f -atime +7
搜索访问时间超过10分钟的所有文件
find . -type f -amin +10
找出比file.log修改时间更长的所有文件
find . -type f -newer file.log
根据文件大小进行匹配
find . -type f -size 文件大小单元
文件大小单元:
- b —— 块(512字节)
- c —— 字节
- w —— 字(2字节)
- k —— 千字节
- M —— 兆字节
- G —— 吉字节
搜索大于10KB的文件
find . -type f -size +10k
搜索小于10KB的文件
find . -type f -size -10k
搜索等于10KB的文件
find . -type f -size 10k
删除匹配文件
删除当前目录下所有.txt文件
find . -type f -name "*.txt" -delete
根据文件权限/所有权进行匹配
当前目录下搜索出权限为777的文件
find . -type f -perm 777
找出当前目录下权限不是644的php文件
find . -type f -name "*.php" ! -perm 644
找出当前目录用户tom拥有的所有文件
find . -type f -user tom
找出当前目录用户组sunk拥有的所有文件
find . -type f -group sunk
查找当前目录或者子目录下所有.txt文件,但是跳过子目录sk
find . -path "./sk" -prune -o -name "*.txt" -print
要列出所有长度为零的文件
find . -empty
执行命令相关
查找当前目录下所有.txt文件并把他们拼接起来写入到all.txt文件中
find . -type f -name "*.txt" -exec cat {} \;> all.txt
将30天前的.log文件移动到old目录中
find . -type f -mtime +30 -name "*.log" -exec cp {} old \;
单行命令中-exec参数中无法使用多个命令,可以将多条命令保存在shell文件中,在-exec执行该文件
-exec ./text.sh {} \;
grep
在每个 FILE 或是标准输入中查找 PATTERN。默认的 PATTERN 是一个基本正则表达式(缩写为 BRE)。例如: grep -i 'hello world' menu.h main.c
常用参数
grep pattern filename # 默认支持正则
grep -e pattern1 -e pattern2 filename
默认情况下,grep命令用基本的Unix风格正则表达式来匹配模式。Unix风格正则表达式采用特殊字符来定义怎样查找匹配的模式。
需要注意的是:限定连续字符范围 的{}符号在 shell 是有特殊意义的,因此, 我们必须要使用字符 \{ 与\} 来让它失去特殊意义才行。
grep --color=auto " 在输出行中着重标记出匹配到的模式
-a # 将 binary 文件以 text 文件的方式搜寻数据
-e # 指定字符串做为查找文件内容的样式(非正则)。如果要指定多个匹配模式,可用-e参数来指定每个模式,grep -e t -e f file 输出了含有字符t或字符f的所有行。
-E # 将字符串为延伸的正则表达式来使用
-o # 只输出匹配到的文本,如果在同一行中,会分开显示
-v # 打印出不匹配match_pattern的所有行
-c # 统计匹配行的数量,并不是匹配的次数。匹配次数需要与-o配合,请看后面的例子
-n # 打印出匹配字符串所在行的行号,以及该行的内容,如果涉及多个文件,该选项也会随输出结果打印出文件名
-i # 忽略模式中的大小写
-l # 多文件处理时,可以列出匹配模式所在的文件
-L # 与-l相反,它会返回一个不匹配的文件列表
-q # 静默模式(主要用于脚本中,,在命令行中没什么用),只判断是否匹配成功,不会输出任何内容。它仅是运行命令,然后根据命令执行成功与否返回退出状态。0表示匹配成功,非0表示匹配失败。
-r # 递归搜索当前目录和子目录
-w # 匹配整个英文单词,对中文不管用
-x # 匹配整行,比较两个文件不同行时使用
-f # 从文件中读取匹配模式,一行一个模式
# 显示前后几行
-A # after,显示匹配到的行以及之后的 n 行
-B # before,显示匹配到的行以及之前的 n 行
-C # Center,显示匹配到的行以及前后的 n
# 如果匹配到多行,为了区分匹配到的字符串,用"--"进行区分,比如:
echo -e "a\nb\nc\na\nb\nc" | grep a -A 1
# a 匹配到第1次
# b
# --
# a 匹配到第2次
# c
统计匹配项的数量
echo -e "1 2 3 4\nhello\n5 6" | egrep -o "[0-9]" | wc -l
正则表达式选择与解释:
-E, --extended-regexp PATTERN 是一个可扩展的正则表达式(缩写为 ERE)
-F, --fixed-strings PATTERN 是一组由断行符分隔的定长字符串。
-G, --basic-regexp PATTERN 是一个基本正则表达式(缩写为 BRE)
-P, --perl-regexp PATTERN 是一个 Perl 正则表达式
-e, --regexp=PATTERN 用 PATTERN 来进行匹配操作
-f, --file=FILE 从 FILE 中取得 PATTERN
-i, --ignore-case 忽略大小写
-w, --word-regexp 强制 PATTERN 仅完全匹配字词
-x, --line-regexp 强制 PATTERN 仅完全匹配一行
-z, --null-data 一个 0 字节的数据行,但不是空行
杂项:
-s, --no-messages 不显示错误信息
-v, --invert-match 选中不匹配的行
-V, --version 显示版本信息并退出
--help 显示此帮助并退出
--mmap 忽略向后兼容性
输出控制:
-m, --max-count=NUM NUM 次匹配后停止
-b, --byte-offset 输出行的同时打印字节偏移
-n, --line-number 输出行的同时打印行号
--line-buffered 每行输出清空
-H, --with-filename 为每一匹配项打印文件名
-h, --no-filename 输出时不显示文件名前缀
--label=LABEL 标准输入将LABEL 打印为文件名
-o, --only-matching 只显示一行中匹配PATTERN 的部分
-q, --quiet, --silent 不显示所有输出
--binary-files=TYPE 假定二进制文件的TYPE 类型;
TYPE 可以是`binary', `text', 或`without-match'
-a, --text 等同于 --binary-files=text
-I 等同于 --binary-files=without-match
-d, --directories=ACTION 操作目录的方式;
ACTION 可以是`read', `recurse',或`skip'
-D, --devices=ACTION 操作设备、先入先出队列、套接字的方式;
ACTION 可以是`read'或`skip'
-r, --recursive 等同于 --directories=recurse
-R --dereference-recursive likewise, but follow all symlinks
--include=FILE_PATTERN 只查找匹配FILE_PATTERN 的文件
--exclude=FILE_PATTERN 跳过匹配FILE_PATTERN 的文件和目录
--exclude-from=FILE 跳过所有除FILE 以外的文件
--exclude-dir=PATTERN 跳过所有匹配PATTERN 的目录。
-L, --files-without-match 只打印不匹配FILEs 的文件名
-l, --files-with-matches 只打印匹配FILES 的文件名
-c, --count 只打印每个FILE 中的匹配行数目
-T, --initial-tab 行首tabs 分隔(如有必要)
-Z, --null 在FILE 文件最后打印空字符
文件控制:
-B, --before-context=NUM 打印以文本起始的NUM 行
-A, --after-context=NUM 打印以文本结尾的NUM 行
-C, --context=NUM 打印输出文本NUM 行
-NUM 等同于 --context=NUM
--color[=WHEN],
--colour[=WHEN] 使用标志高亮匹配字串;
WHEN 可以是`always', `never'或`auto'
-U, --binary 不要清除行尾的CR 字符(MSDOS 模式)
-u, --unix-byte-offsets 当CR 字符不存在,报告字节偏移(MSDOS 模式)
扩展用法
egrep命令是grep的一个衍生,支持POSIX扩展正则表达式。POSIX扩展正则表达式含有更 多的可以用来指定匹配模式的字符,增加了额外的正则表达式元字符集。
grep -E "[a-z]+" filename
#或
egrep "[a-z]+" filename
不使用正则表达式
grep -F 'str'
fgrep 'str'
fgrep 查询速度比grep命令快,但是不够灵活:它只能找固定的文本,而不是正则表达式。
如果你想在一个文件或者输出中找到包含星号字符的行
fgrep '*' /etc/profile
#或
grep -F '*' /etc/profile
fgrep则是另外一个版本,支持将匹配模式 指定为用换行符分隔的一列固定长度的字符串。这样就可以把这列字符串放到一个文件中,然后 在fgrep命令中用其在一个大型文件中搜索字符串了。
多模式匹配
逻辑或
命令会打印出匹配任意一种模式的行,每个匹配对应一行输出。例如:
echo this is a line of text | grep -o -e "this" -e "line" this
从文件中读取匹配模式
可以将多个模式定义在文件中。选项-f可以读取文件并使用其中的模式(一个模式一行,记得最后留一行空白行,不然最后一种模式匹配不到,很诡异)
cat pat_file
# ^h.*
# co+l
#
echo hello \n this is cool | grep -f pat_file
# hello
# this is cool
逻辑与
grep 本身并不支持,所以需要通过管道符号或者与 find 组合使用
常用功能
检索文件内容
递归搜索目录中的文件内容(不是文件名)-,注意:支持相对路径、绝对路径,但不支持~/work/这样的路径。
grep "查找内容" 目录 -r -n --include=*.{py,sh} --exclude=*.{log,txt} --exclude-dir={log,tmp,config} --exclude-from BLACK_LIST
--include指定搜索的文件类型或者某个文件,比如*.sh,*.py,可以使用GLOB写法,如*.{py,sh}--exclude指定不想搜索的文件类型或者某个文件,比如*.txt,bigdata.txt,可以使用GLOB写法,如*.{txt,log}--exclude-dir可以排除不想搜索的目录,多个目录时请用{a,b,c}--exclude-from BLACK_LIST从黑名单文件中读取要排除文件列表
例子:
grep "TODO" ./ -r -n --include=*.{sh,py} --exclude-dir={tmp,logs}
# ./src/test.c:16:TODO 添加注释;
等价于find . -type f | xargs grep "test_function()"
0值字节后缀的 xargs
xargs命令可以为其他命令提供命令行参数列表。
当文件名作为命令行参数时,建议用0值字节作为文件名终结符,而非空格。因为一些文件名中会包含空格字符,一旦它被误解为终结符, 那么单个文件名就会被视为两个(例如,New file.txt被解析成New和file.txt两个文件名)。
这个问题可以利用0值字节后缀来避免。
grep和find命令可以生成带有0值字节后缀的输出,然后传递 给 xargs,让它产生文件名列表。为了指明输入中的文件名是以0值字节作为终结,需 要在xargs中使用选项-0。
# 创建测试文件:
echo "test" > file1
echo "cool" > file2
echo "test" > file3
# 找出包含有 test 内容的文件名,并以0值字节作为终结符,然后传递给 xargs,让它生成文件名参数列表,之后传递(不用管道符号)给 rm 命令,删除这些文件
grep "test" file* -lZ | xargs -0 rm
# 选项-l告诉grep只输出有匹配出现的文件名。选项-Z使得grep使用0值字节(\0)作为文 件名的终结符。这两个选项通常都是配合使用的。xargs的-0选项会使用0值字节作为输入的分隔符
比较两个文件相同内容与不同内容
输出file2中不含file1的内容
grep -Ff file1 file2 # 输出公共的行
grep -vFf file1 file2 # 输出不在 file1 的行
grep -xvFf file1.txt file2.txt > result.tx
-x, --line-regexp 强制 PATTERN 仅完全匹配一行
查找满足条件的文件是否匹配到文字
查找包含”hello world”的文件清单,并从这些清单中查找出满足”mailx”的匹配情况
#方法1:直接利用管道
grep -i "hello world" -rl /home/tyrone | xargs grep -i "mailx"
#输出结果
/home/tyrone/test1.txt:mailx
#方法2:使用find,适合于需要灵活判断条件的场景。例如查找指定路径下,同时匹配多个模式的txt文件。
#注意:本例中“mailx”后面的命令必须加上反引号 ` ,否则会被当作要查询的文件名。
grep -i "mailx" `find /home/tyrone -type f -name "*.txt" -exec grep -l "hello world" {} \;`
#输出结果
/home/tyrone/test1.txt:mailx
#方法3:同2
find /home/tyrone -name "*.txt" -exec grep -l "hello world" {} \; | xargs grep -i "mailx"
#输出结果
/home/tyrone/test1.txt:mailx
tr
基本用法
tr是translate(转换)的简写,基本功能是将字符从一个字符集合映射到另一个集合中
tr set1 set2
注意:
tr只能通过stdin接收输入,无法通过命令行参数接收 ,如tr -s '' file,只能转为stdin形式,tr -s ' '< file.txt
如果两个字符组的长度不相等,那么set2会不断复制其最后一个字符,直到长度与set1 相同。如果set2的长度大于set1,那么在set2中超出set1长度的那部分字符则全部被忽略。
echo "HELLO WHO IS THIS" | tr 'A-Z' 'a-z'
字符集合(字符组)可以使用“起始字符—终止字符”,如果不是有效的连续字符序列, 那么它就会被视为起始字符、—、终止字符这3个元素的集合。也可以使用像\t、\n 这种特殊字符或其他ASCII字符。可以按照需要追加字符或字符类来构造自己的字符组。
| 字符类 | 说明 |
|---|---|
| alnum | 字母和数字 |
| alpha | 字母 |
| cntrl | 控制(非打印)字符 |
| digit | 数字 |
| graph | 图形字符 |
| lower | 小写字母 |
| 可打印字符 | |
| punct | 标点符号 |
| space | 空白字符 |
| upper | 大写字母 |
| xdigit | 十六进制字符 |
字符类的使用方法tr '[:lower:]' '[:upper:]'
其他参数
tr [options] set1 [set2]
-d # 删除(delete)set1 中的字符
-c # tr会将不在set1中的字符转换成set2中的字符,set2只能是一个字符
-d -c # 只保留set1的字符,不需要set2
-s # 删除重复字符,只留下一个
例子
tr命令可以用来加密。ROT13是一个著名的加密算法。在ROT13算法中,字符会被移动13 个位置,因此文本加密和解密都使用同一个函数:
echo "tr came, tr saw, tr conquered." | tr 'a-zA-Z' 'n-za-mN-ZA-M'
将制表符转换成单个空格:
tr '\t' ' ' < file.txt
删除字符
echo "Hello 123 world 456" | tr -d '0-9'
# Hello world
只保留set1 的字符
echo hello 1 char 2 next 4 | tr -d -c '0-9 \n'
# 124
压缩空格
echo "GNU is not UNIX. Recursive GNU is not UNIX. Recursive right ?" | tr -s ' '
cut
cut命令可以按列,而不是按行来切分文件。该命令可用于处理使用固定宽度字段的文件、 CSV文件或是由空格分隔的文件。
如果空格的长度不一致,需要使结合
tr命令,进行字符串转换
每列被称为一个字段,默认分隔符是制表符\t
-d"\t" # 指定分割符为"\t",默认就是制表符,因此可以不写
-f2,3 # 显示2,3列的内容,f2可以不用空格分开
-f2-4 # 显示第2到4列(field)的内容,2-5 的用法看后面表格说明
-c2-5 # 显示第2到5个字符(character),注意不能与-d 组合
-b2-5 # 显示第2到5个字节(byte),注意不能与-d 组合
--complement # 与-f 组合使用,显示f没有指定的列,就是取反
--output-delimiter 指定输出时的列分隔符
cut range_fields.txt -c1-3,6-9 --output-delimiter ","
# abc,fghi
# abc,fghi
# abc,fghi
# abc,fghi
| 选取方式 | 说明 |
|---|---|
| N- | 从第N个字节、字符或字段开始到行尾 |
| N-M | 从第N个字节、字符或字段开始到第M个(包括第M个在内)字节、字符或字段 |
| -M | 从第1个字节、字符或字段开始到第M个(包括第M个在内)字节、字符或字段 |
cut -c -2 range_fields.txt # 打印前2个字符
cut -c2-5 range_fields.txt # 打印第2个到第5个字符
文件分割 split
split [options] filename prefix.
将文件分割成固定大小(bytes)或者固定行数的小文件,原文件不动,小文件为prefix.aa prefix.ab等形式,前缀后面最好要有.,如file.
-d 使用数字后缀,file.01 file.02,默认为字符后缀
-l 指定每个输出文件多少行内容,最后一个文件可能会小于n
-b, --bytes=SIZE 指定每个输出文件的大小,如-b100K,大小可以是 KB、MB,GB
-C,--line-bytes=SIZE TODO
-a 指定后缀长度,默认是2,不指定时程序会自适应
--verbose 显示创建文件的信息
sed
sed是stream editor(流编辑器)的缩写。它最常见的用法是进行文本替换。默认不修改原文件,只显示修改后的结果。
sed [-hnV][-e<script>][-f<script文件>][文本文件]
-e 'script1;script2'
-f script_file # 从文本中读取大量指令,一行一个,以换行结束
-i # 保存到原文件
-n或--quiet或--silent # 仅显示script处理后的结果。
要是我们想就地(in place)修改文件内容,可以使用选项-i保存到原文件中。值得推荐的做法是
先使用不带
-i选项的sed命令,以确保正则表达式没有问题,如果结果符合要求,再加入-i选项将更改写入文件。也可以使用
sed -i.bak 's/abc/def/' file,这时的sed不仅替换文件内容,还会创建一个名为file.bak的文件,其中包含着原始文件内容的副本。
替换s
s/old/new/ # 替换每行第1个匹配到的字符串
s/old/new/2 # 替换每行第2个匹配到的字符串
s/old/new/g # 替换全部
s/old/new/2g # 只替换第2次及之后匹配到的字符串
echo thisthisthisthis | sed 's/this/THIS/2g'
# thisTHISTHISTHIS
替换标记
s/pattern/replacement/flags
有4种可用的替换标记:
- 数字,表明新文本只替换每行第几处模式匹配的地方;
- g,表明新文本将会替换所有匹配的文本;
- p,表明原先行的内容要打印出来;
- w file,将匹配到的行替换的结果写到指定的file中。
p替换标记会打印与替换命令中指定的模式匹配的行替换后的结果。这通常会和sed的-n选项一起使用。-n选项将禁止sed编辑器输出。但p替换标记会输出修改过的行。将二者配合使用的效果就是 只输出被替换命令修改过的行。
$ cat data5.txt
This is a test line.
This is a different line.
$ sed -n 's/test/trial/p' data5.txt
This is a trial line.
w替换标记会产生与 p 模式同样的输出,不过会将输出保存到指定文件中。
分隔符
sed命令会将s之后的字符视为命令分隔符。这允许我们更改默认的分隔符/:
sed 's:text:replace:g'
sed 's|text|replace|g'
如果作为分隔符的字符出现在模式中,必须使用\对其进行转义
指定行
方式1(数字):
在s前添加行编辑即可
sed '2s/dog/cat/' data1.txt # 只修改地址指定的第2行的文本
sed '2,3s/dog/cat/' data1.txt # 只修改地址指定的第2,3行的文本
sed '2,$s/dog/cat/' data1.txt # 修改从某行开始的所有行
方式2(正则):
sed '/pattern/s/bash/csh/' /etc/passwd # 使用 pattern 正则表达式过滤
已匹配字符串标记(&)
在sed中,我们可以用&指代模式所匹配到的字符串,这样就能够在替换字符串时使用已匹 配的内容:
echo this is an example | sed 's/\w+/[&]/g'
# [this] [is] [an] [example]
子串匹配标记(\num)
匹配正则中的子表达式,第1 个是\1,第 2 个是\2,以此类推
echo this is digit 7 in a number | sed 's/digit \([0-9]\)/\1/'
# this is 7 in a number
多表达式
sed 'expression; expression'
sed 'expression' | sed 'expression'
sed -e 'expression' -e 'expression'
sed -e 'expression; expression'
sed -e '
> s/brown/green/
> s/fox/elephant/
> s/dog/cat/' data1.txt
例子
echo abc | sed 's/a/A/;s/c/C/'
echo abc | sed 's/a/A/' | sed 's/c/C/'
echo abc | sed -e 's/a/A/' -e 's/c/C/'
echo abc | sed -e 's/a/A/; s/c/C/'
# AbC
单引号与双引号的区别
sed表达式通常用单引号来引用。如果想在sed表达式中使用变量,双引号就能派上用场了。
text=hello
echo hello world | sed "s/$text/HELLO/"
# HELLO world
多命令
如果需要在匹配到的行上执行多条命令,可以用{}将多条命令组合在一起,同时指定过滤的行号,或者匹配模式。
多条命令之间用;分割,或者分成多行书写。
# 一行内多个命令
sed -n '/root/{s/bash/blueshell/;p;q}' /etc/passwd
# 分成多行执行多个命令
sed '3,${
> s/brown/green/
> s/lazy/active/
> }' data1.txt
插入a与i
sed '[address]command\
new line'
插入(insert)命令(i)会在指定行前插入文本,(插入的文本要带有换行,否则就直接插入在指定行的头部)
附加(append)命令(a)会在指定行后添加文本,(如果文本没换行,会与下一行在同一行)
可以指定一个行地址,匹配一个数字行号或文本模式
这两条命令的费解之处在于它们的格式。它们不能在一行内使用。你必须先输入
i或者a,然后使用\进行换行,接着输入要插入或者附加的内容。
# 脚本中的写法
$ echo "Test Line 2" | sed '1i\ # 在第一行前插入
Test Line 1\ # 换行,否则两行文本会在一同一行
'
Test Line 1
Test Line 2
$ echo "Test Line 2" | sed '/Line/a\ # 在包含Line的一行添加
Test Line 1\
'
Test Line 2
Test Line 1
插入多行
插入或附加多行文本,就必须对要插入或附加的新文本中的每一行使用反斜线,直到最后 一行。
sed '1i\
> This is one line of new text.\
> This is another line of new text.' data6.txt
This is one line of new text.
This is another line of new text.
This is line number 1.
This is line number 2.
This is line number 3.
This is line number 4.
删除行 d
删除命令d名副其实,它会删除匹配指定寻址模式的所有行。
支持指定行sed '2,3d' data6.txt
通过特定行区间指定:sed '2,3d' data6.txt
模式匹配特性也适用于删除命令sed '/number 1/d' data6.txt
也可以使用两个文本模式来删除某个区间内的行,但这么做时要小心。
- sed编辑器会删除两个指定行之间 的所有行(包括指定的行)。如果没有找到停止模式,所以就将数据流中的剩余行全部删除了。
- 你指定的第1个模式 会“打开”行删除功能,第2个模式会“关闭”行删除功能。之后再遇到第1个模式会再打开删除功能。
$ cat data7.txt
This is line number 1.
This is line number 2.
This is line number 3.
This is line number 4.
This is line number 1 again. # 再次触发删除功能
This is text you want to keep.
This is the last line in the file.
$ sed '/1/,/3/d' data7.txt
This is line number 4.
字符转换y
转换(transform)命令(y)是唯一可以处理单个字符的sed编辑器命令。
[address]y/inchars/outchars/
sed 'y/123/789/' data8.txt
This is line number 7.
This is line number 8.
This is line number 9.
This is line number 4.
This is line number 7 again.
This is yet another line.
This is the last line in the file.
转换命令会对inchars和outchars值进行一对一的映射。
如果inchars和outchars的长度不同,则sed编辑器会产生一 条错误消息。
转换命令是一个全局命令,你无法限定只转换在特定地方出现的字符。
打印命令
- p命令用来打印文本行;
- 等号(=)命令用来打印行号;
- l(小写的L)命令用来列出行。
p 命令
echo "this is a test" | sed 'p'
this is a test
this is a test
它所做的就是打印已有的数据文本
最常见的用法是与-n配合打印包含匹配文本模式的行。用-n选项,你可以禁止输出其他行,只打印包含匹配文本模式的行。
$ cat data6.txt
This is line number 1.
This is line number 2.
This is line number 3.
This is line number 4.
$ $ sed -n '/number 3/p' data6.txt
This is line number 3.
修改前后对比
$ sed -n '/3/{
> p
> s/line/test/p
> }' data6.txt
This is line number 3.
This is test number 3. $
=等号
等号命令会打印行在数据流中的当前行号。
sed '=' data1.txt
1
The quick brown fox jumps over the lazy dog.
2
The quick brown fox jumps over the lazy dog.
$ sed -n '/number 4/{
> =
> p
> }' data6.txt 4
This is line number 4.
显示特殊字符l
命令(l)可以打印数据流中的文本和不可打印的ASCII字符。任何不可打印 字符要么在其八进制值前加一个反斜线,要么使用标准C风格的命名法(用于常见的不可打印字符),比如\t,来代表制表符。
制表符的位置使用\t来显示。行尾的美元符表示换行符。
$ cat data10.txt
This line contains an escape character.
$ sed -n 'l' data10.txt
This line contains an escape\tcharacter. \a
保存命令w
w命令用来向文件写入行。该命令的格式如下:
[address]w filename
filename可以使用相对路径或绝对路径,但不管是哪种,运行sed编辑器的用户都必须有文 件的写权限。
地址可以是sed中支持的任意类型的寻址方式,例如单个行号、文本模式、行区间或文本模式。
$ cat data11.txt
Blum, R Browncoat
McGuiness, A Alliance
Bresnahan, C Browncoat
Harken, C Alliance
$ sed -n '/Browncoat/w Browncoats.txt' data11.txt
$ cat Browncoats.txt
Blum, R Browncoat
Bresnahan, C Browncoat
读取命令
读取(read)命令(r)允许你将另一个文件中的数据插入到数据流中。
[address]r filename
地址区间只能指定单独一个行号或文本模式地址。sed编辑器会将文件中的所有文本行插入到指定地址后。
$ cat data12.txt
This is an added line.
This is the second added line.
$ sed '3r data12.txt' data6.txt
This is line number 1.
This is line number 2.
This is line number 3.
This is an added line.
This is the second added line.
This is line number 4.
$ sed '/number 2/r data12.txt' data6.txt
This is line number 1.
This is line number 2.
This is an added line.
This is the second added line.
This is line number 3.
This is line number 4.
另一个很酷的用法是和删除命令配合使用:利用另一个文件中的数据来替换文件中的占位文本。
$ cat notice.std
Would the following people:
LIST
please report to the ship's captain.
$ sed '/LIST/{
> r data11.txt
> d
> }' notice.std
Would the following people:
Blum, R Browncoat
McGuiness, A Alliance
Bresnahan, C Browncoat
Harken, C Alliance
please report to the ship's captain. $
现在占位文本已经被替换成了数据文件中的名单。
Join 字段合并
根据指定的字段 拼接两个文件。前提是2个文件中指定的拼接字段是排序过的。
拼接字典默认是第一列,可以通过以下方式修改:
-12表示第一个文件使用第2个字段进行拼接。-22表示第二个文件使用第2个字段进行拼接。
cat a
aaa 111
bbb 222
cat b
555 aaa
666 bbb
777 ccc
join -1 -2 a b
文本编码转换 iconv
对于文本文件转码,你可以试一下 iconv。或是试试更强的 uconv 命令(这个命令支持更高级的Unicode编码)
iconv -f ISO-8859-1 -t UTF-8 file
临时文件 mktemp
mktemp [-qu][文件名参数]
参数:
-d创建临时目录-q执行时若发生错误,不会显示任何信息。-u暂存文件会在mktemp结束前先行删除,不推荐使用- [文件名参数] 文件名参数必须是以”自订名称.XXXXXX”的格式,XXX 会被替换为随机字符串。
mktemp jizx.XXX
# jizx.ztI
磁盘
mount
默认情况下,mount命令会输出当前系统上挂载的 设备列表。
mount -t type device directory # 格式说明
mount -t vfat /dev/sdb1 /media/disk
umount [directory | device ],umount命令支持通过设备文件或者挂载点来指定要卸载的设备。
在卸载设备时,系统提示设备繁忙,无法卸载设备,可用lsof命令获得使用它的进程信息,在应用中停止使用该设备或停止该进程。
lsof /path/to/device/node
lsof /path/to/mount/point
df与 du TODO
df命令很容易发现哪个磁盘的存储空间快没了
du TODO
du命令可以显示某个特定目录(默认情况下是当前目录)的 磁盘使用情况。
压缩命令
压缩命令 linux 命令行与 shell 脚本编程大全 4.33
其他命令
file 查看文件类型
seq
以指定增量从首数开始打印数字到尾数。
seq [选项]... 尾数
seq [选项]... 首数 尾数
seq [选项]... 首数 增量 尾数
-f, --format=格式 使用 printf 样式的浮点格式
-s, --separator=字符串使用指定字符串分隔数字(默认使用:\n)
-w, --equal-width 在列前添加0,使得宽度相同
案例:
$ seq 5
1
2
3
4
5
$ seq 5 8
5
6
7
8
$ seq 5 2 10
5
7
9
$ seq 5 -1 1 # -1 逆序时-1必须存在
5
4
3
2
1
xarg
xargs 是给命令传递参数的一个过滤器,也是组合多个命令的一个工具。
它能够捕获一个命令的输出,然后传递给另外一个命令。
args 一般是和管道一起使用。
somecommand |xargs -item command
选项:
-d delim # 指定分隔符,默认的xargs分隔符是回车,argument的分隔符是空格,这里修改的是xargs的分隔符。
-i 或者-I # 配合占位符使用,将参数替换到命令的占位符上,对每一个参数,命令都会被执行一次。
# 个人理解:因为 xargs 默认将参数放在其他命令的最后,但是像 cp 这种需要在中间的位置时,就可以用-I选项,具体看后面的例子。
-t # 打印 xargs 后面那个命令拼上参数后的完整形式,然后再执行,用于debug
-s # num 指定 xargs 后面那个命令的最大命令行字符数。
-0 # 将 \0 作为定界符。
-p # 当每次执行一个argument的时候询问一次用户。
-L num # 从标准输入一次读取 num 行送给 command 命令。
-n num # 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。
参数的功能分类:
如何分割(xargs、xargs -d、xargs -0)
分割后如何划批(xargs -n、xargs -L)
- 参数如何传递(xargs -i)。
- 另外xargs还提供询问交互式处理(-p选项)和预先打印一遍命令的执行情况(-t选项),传递终止符(-E选项)
实验文件准备
mkdir tmp
cd tmp
rm -fr *
mkdir a b c d test logdir shdir
touch "one space.log"
touch logdir/{1..10}.log
touch shdir/{1..5}.sh
echo "the second sh the second line" > shdir/2.sh
cat <<eof>shdir/1.sh
> the first sh
> the second line
> eof
流程讲解
先分割,再分批,然后传递到参数位
预处理
管道传递过来的stdin经过xargs处理后的:将所有空格(多个空格)、制表符和分行符都替换为(一个)空格并压缩到一行上显示,这一整行将作为一个整体,这个整体的所有空格属性继承xargs处理前的符号属性.
如果想要保存制表符、空格等特殊符号,需要将它们用单引号或双引号包围起来,但是被xargs处理后,一行的整体中单双引号(和反斜线)都会被去掉。
分割
文本意义上的符号和标记意义上的符号
在解释xargs和它的各种选项之前,先介绍一个贯穿xargs命令的符号分类:文本意义上的空格、制表符、反斜线、引号和非文本意义上的符号。我觉得理解它们是理解xargs分割和分批原理的关键。
文本意义上的空格、制表符、反斜线、引号:未经处理就已经存在的符号,例如文本的内容中出现这些符号以及在文件名上出现了这些符号都是文本意义上的。
与之相对的是非文本意义的符号,由于在网上没找到类似的文章和解释,所以我个人称之为标记意义上的符号:处理后出现的符号,例如
ls命令的结果中每个文件之间的制表符,它原本是不存在的,只是ls命令处理后的显示方式。还包括每个命令结果的最后的换行符,文件内容的最后一行结尾的换行符。
两种分批可能:
- 指定
-n时按空格分段,然后划批,不管是文本意义的空格还是标记意义的空格,只要是空格都是-n的操作对象 - 指定
-L或者-i时按段划批,文本意义的符号不被处理,比如one space.txt这个文件不会被分割。
ls | xargs -n 2
ls | xargs -L 2
ls | xargs -i -p echo {}
如果在一个xargs中使用了多个分批选项,则它们之间必然会冲突,它们的规则是写在后面的生效,前面的分批选项被忽略。
-d 整体执行的过程:
替换:将所有标记符号替换为
\n,完成后所有符号(空格、制表符、换行符)都是文本符号分段:根据分隔符进行分段、并用空格分开每段。由于分段前所有符号都是文本符号,因此分段后的文本中可能包含空格、制表符、换行符。也就是说除了-d 导致的分段空格,其余的所有符号都是分段中的一部分
- 输出:最后根据
-n、-L、-i指定的分批选项来输出。
-0等价于-d"\0",-0可以处理接收的stdin中的null字符(\0)。如果不使用 -0选项或- -null选项,检测到\0后会给出警告提醒,并只向命令传递非\0段。
分批行为
分批用于指定每次传递多少个分段。有三种分批选项:-n,-L和-i。
-n 默认以空格分段划分,与-d、-0一起时,按指定的分隔符分段划分
-L 永远是按段划分的
-i 如果不使用-i,则默认是将分割后处理后的结果整体传递到命令的最尾部。但是有时候需要传递到多个位置,不使用-i就不知道传递到哪个位置了。例如重命名备份的时候在每个传递过来的文件名加上后缀.bak,这需要两个参数位。
ls logdir/ | xargs -i mv ./logdir/{} ./logdir/{}.bak # 将分段传递到多个参数位
分批的典型应用
分批选项有时特别有用,例如脚本规定每次只能传输三个参数。有时候rm -rf的文件数量特别多的时候会提示参数列表太长而导致失败,这时就可以分批来按批删除。
假设目前在/tmp/longshuai/下有29W个.log文件,如果直接删除将会提示参数列表过长。
ls | xargs -n 10000 rm -rf
终止行为之 :xargs -E
-E会将结果空格、制表符、分行符替换为空格并压缩到一行上显示。据我测试,-E似乎只能和独立的xargs使用,和-0、-d配合使用时都会失效。-E优先于-n、-L和-i执行。如果是分批选项先执行,则下面的第二个结果将压缩在一行上。- 指定的终止符必须是完整的,例如想在遇到“xyz.txt”的符号终止时,只能指定完整的xyz.txt符号,不能指定.txt或者txt这样的符号。
- 分两种情况:如果没指定分批选项或者指定的分批选项是-n或者-L时,则段是以空格为分割符,两个空格之间的段都是完整的。
- 如果指定的分批选项是-i,则以段为分割符。
ls
a b c d logdir one space.log shdir sh.txt test vmware-root x.txt
ls | xargs -E one #不指定分批选项
a b c d logdir
ls | xargs -n 2 -E one #指定-n,one后面的所有的都终止传递
a b
c d
logdir
ls | xargs -L 2 -E"one" #同-n 选项
a b
c d
logdir
ls | xargs -i -E"one space.log" echo {} #和-i配合使用时指定完整的段才可以
a
b
c
d
logdir
ls | xargs -i -E"one" -p echo {} #非完整段终止失效
echo a ?...
echo b ?...
echo c ?...
echo d ?...
echo logdir ?...
echo one space.log ?...
echo shdir ?...
echo sh.txt ?...
echo test ?...
echo vmware-root ?...
echo x.txt ?...
总结
| 分割行为 | 标记符号处理方式 | 分段方法 | 分批方法 |
|---|---|---|---|
| xargs | 空格、制表符、分行符替换为空格,引号和反斜线删除。处理完后只有空格。如果空格、制表符和分行符使用引号包围则可以保留 | 结果继承处理前的符号性质(文本符号还是标记符号) | -n以分段结果中的每个空格分段,进而分批。不管是文本还是标记意义的空格.-L -i以标记意义上的空格分段,进而分批 |
| xargs -d | 不处理文本符号,所有标记符号替换为换行符\n,将-d指定的分割符替换为标记意义的空格。结果中除了最后的空行和-d指定的分割符位的分段空格,其余全是文本意义上的符号 |
按照-d指定的符号进行分段,每个段中可包含文本意义上的空格、制表符、换行符。 | 以标记意义上的符号(即最后的空行和-d指定分隔符位的空格)分段,进而分批。分段结果中保留所有段中的符号,包括制表符和分行符。 |
| xargs -0 | 不处理文本意义上的符号,将非\0的标记意义上的符号替换为\n,将\0替换为空格。 |
以替换\0位的空格分段,每个段中可能包含文本意义上的空格、制表符、换行符。 |
检测到\0时,以标记意义上的符号(即最后的空行和\0位的空格)分段,进而分批。分段结果中保留所有段中的符号,包括制表符和分行符。未检测到\0时,整个结果作为不可分割整体,使用分批选项是无意义的 |
多进程
只要能分批的选项,都可以使用”-P”,包括”-n”、”-L”和”-i”。
使用xargs的分批行为,除了可以解决一些问题,还可以一次性将多个分批交给不同进程去处理,这些进程可以使用多个cpu执行,效率可谓大幅提高。
“-P N”选项可以指定并行处理的进程数量为N。不指定”-P”时,默认为1个处理进程,也就是串行执行。指定为0时,将尽可能多地开启进程数量。
xargs与文件名
由于xargs默认将空格作为分隔符,所以不太适合处理文件名,因为文件名可能包含空格。
find命令有一个特别的参数-print0,指定输出的文件列表以null分隔。然后,xargs命令的-0参数表示用null当作分隔符。
$ find /path -type f -print0 | xargs -0 rm
xargs与复杂命令
如果xargs要将命令行参数传给多个命令,可以使用-I参数,并配合sh -c 执行命令
-I指定每一项命令行参数的替代字符串。
$ cat foo.txt
one
two
three
$ cat foo.txt | xargs -I file sh -c 'echo file; mkdir file'
one
two
three
$ ls
one two three
我们希望对每一项命令行参数,执行两个命令(echo和mkdir),使用-I file表示file是命令行参数的替代字符串。执行命令时,具体的参数会替代掉echo file; mkdir file里面的两个file。
xargs与重定向
如果脚本中包含重定向的命令,那么整个命令必须用双引号扩起来,如果双引号里面有$需要用\来转义,就比如下面的$5
seq 5 10 |xargs -i sh -c "awk -F\$'\t' '\$5=={}' file > file_part_{}"
不过awk本身支持将不同的内容保存到不同的文件中
awk 'NR!=1{print $4,$5 > $6}' netstat.txt
xargs的限制
其实是xargs的限制和缺点,但因为通过”-i”选项方便演示,所以此处使用”-i”选项。注意,不是”-i”选项的缺陷。
由于xargs -i传递数据时是在shell执行xargs命令的时候,根据shell解析命令行的流程 ,xargs后的命令如果有依赖于待传递数据的表达式,则无法正确执行。
第一:无法通过xargs传递数值做正确的算术扩展:
echo 1 | xargs -I "x" echo $((2*x))
0
第二:无法将数据传递到命令替换中。
echo /etc/fstab | xargs -i `cat {}`
cat: {}: No such file or directory
参考下图的shell命令行解析过程。

这时要通过xargs正确实现目标,只能改变方法或寻找一些小技巧,例如:
[root@xuexi ~]# echo 1 | xargs -i expr 2 \* {} # 感谢楼下评论者提供的expr思路
2
[root@xuexi ~]# echo /etc/fstab | xargs -i cat $(echo {})
第三:xargs无法处理bash内置命令。例如:
[root@xuexi ~]# echo /etc | xargs -i cd {}
xargs: cd: No such file or directory
例子
复制所有图片文件到 /data/images 目录下:
ls *.jpg | xargs -n1 -I {} cp {} /data/images
# ls 出来的每一行文件名,都会通过 xargs 传递给 cp 命令
统计一个源代码目录中所有 php 文件的行数:
find . -type f -name "*.php" -print0 | xargs -0 wc -l
删除带空格的文件
删除带空格的文件名,思路是让找到的“one space.log”成为一个段,而不是两个段。我给出了常见的两种。
方法一:通过常用的find的-print0选项使用\0来分隔而不是\n分隔,再通过xargs -0来配对保证one space.log的整体性。因为-print0后one space.log的前后各有一个\0,但是文件名中间没有。
[root@xuexi tmp]# find -name "* *.log" -print0 | xargs -0 rm -rf
当然,能使用-0肯定也能使用-d了。
[root@xuexi tmp]# find -name "* *.log" -print0 | xargs -d "x" rm -rf #随意指定非文件名中的字符都行,不一定非要\0
方法二:不在find上处理,在xargs上处理,只要通过配合-i选项,就能宣告它的整体性。
[root@xuexi tmp]# find -name "* *.log" | xargs -i rm -rf "{}"
相较而言,方法一使用的更广泛更为人所知,但是方法二更具有通用性,对于非find如ls命令也可以进行处理。
还可以使用tr将find的换行符换成其他符号再xargs分割配对也行。
除了find -print0可以输出\0字符,Linux中还有其他几个命令配合参数也可以实现:locate -0,grep -z或grep -Z,sort -z等。
其他小例子
# cat test.txt | xargs -n3
a b c
d e f
g h i
j k l
# echo "nameXnameXnameXname" | xargs -dX
name name name name
参考:https://www.cnblogs.com/f-ck-need-u/p/5925923.html#auto_id_4
http://www.ruanyifeng.com/blog/2019/08/xargs-tutorial.html
tee
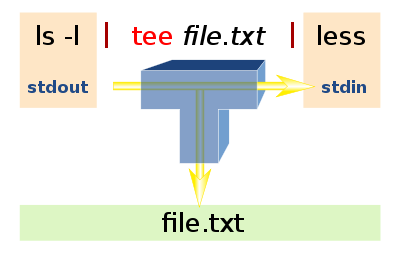
tee命令可以把数据重定向到给定文件和屏幕上,相当于分流了
-a:向文件中重定向时使用追加模式;
scp
TODO scp 的完整命令
scp免密码
- 在A中执行命令:
ssh-keygen -t rsa -P ""
这会在 ~/.ssh 目录下生成两个文件:id_rsa 和 id_rsa.pub
- 拷贝A的id_rsa.pub到B:
scp ~/.ssh/id_rsa.pub yliu@192.168.200.1:/home/yliu
- 登录B,并把id_rsa.pub输入到B的authorized_keys文件中:
cat /home/yliu/id_rsa.pub >> /home/yliu/.ssh/authorized_keys
- 最后一步:如果是第一次生成authorized_keys,需要授权:chmod 600 authorized_keys
大功告成!此时在复制文件就无需输入密码了。而且,在A中ssh登录B也无需密码了。
反之亦然,在B中设置A的免密码登录完全一样,在此不做赘述。
其他知识点
一行内指令
一行内指定依次运行的一系列指令
$ pwd ; ls ; cd /etc ; pwd ; cd ; pwd ; ls
命令行中输入tab
我们知道,在bash命令行下,Tab键是用来做目录文件自动完成的事的。但是如果你想输入一个Tab字符(比如:你想在sort -t选项后输入字符),你可以先按`Ctrl-V`,然后再按Tab键,就可以输入字符了。当然,你也可以使用$'\t'。
EOF(End-of-File)字符。Ctrl+D组合键会在bash中产生一个EOF字符。