正则表达式必知必会
正则表达式必知必会的笔记
元字符表
下面介绍的是在正则表达式中有特殊意义的字符,称为元字符


转义符号
如果要查找这些字符本身,需要用\进行转义,比如想匹配点号. 就需要这样写\. 有个特殊的例子:如果想匹配\就需要这样\\
匹配单个字符
匹配字符中的一个
.: 匹配任意一个字符(除了换行符)[]: 匹配多个字符中的一个- 自定义字符:[akm],匹配a、k、m中的一个
- 字符区间:[ASCII1-ASCII2],可以是ASCII中的任意字符作为起始字符(ASCII1小于ASCII2),常用的有:[a-z]、[A-Z]、[0-9]、[A-Za-z](可以有多个字符区间)
- 取反操作:[^a-z] 表示匹配不是a到z的任意字符,^的作用效果是整个区间,而不仅仅是跟在其后的字符
-是一个元字符,表示区间,不会匹配减号,因此不需要转义
^是一个元字符,表示在[ ]中表示非匹配,不会匹配到^,因此不需要转义
匹配空白字符
也就是不可见的字符
| 符号 | 用途 |
|---|---|
| \f | 匹配一个换页符。 |
| \n | 匹配一个换行符。 |
| \r | 匹配一个回车符。 |
| \t | 匹配一个制表符。 |
| \v | 匹配一个垂直制表符。 |
匹配特定一类的字符
不可见字符
| 符号 | 用途 |
|---|---|
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [ ^\f\n\r\t\v]。 |
数字
| \d | 等价于[0-9] |
|---|---|
| \D | 等价于[^0-9] |
字符
匹配大小写字母、数字、下划线
| \w | 等价于[a-zA-Z0-9_] |
|---|---|
| \W | 等价于[^a-zA-Z0-9_] |
匹配中文
需要切换匹配模式为‘u’,表示要匹配的内容为unicode编码内容,汉字的unicode起始编码是:0x4e00—0x9fa5,因此要匹配全部为中文的正则为:$patern = "/[\x{4e00}-\x{9fa5}]/u"
或匹配“|”的一个坑
正则是从前向后进行匹配的,因此如果文本是餐饮店,而正则是餐|餐饮 或餐饮|餐 ,那就谁在前就先匹配到谁,因此结果分别是:餐、餐饮
但是,如果正则是饮店|店或店|饮店呢,他们的结果都是饮店,原因就是从先向后扫描时,饮店这个字会先触发,完成匹配,而不会再取匹配店了。
重复匹配
| 符号 | 用途 |
|---|---|
| + | 出现1至多次 |
| * | 出现0至多次 |
| ? | 出现0或1次 |
| {n} | 精确控制出现n次 |
| {n,m} | 区间控制,出现n至m次 |
| {n,} | 至少出现n次 |
贪心匹配
+、*、{n,}会贪婪的进行匹配,比如下面的例子:
<b>text1</b> <b>text2</b>
<[Bb]>.*</[Bb]> 会匹配着整体字符串,而不是两个<b>text1</b> <b>text2</b>
因此需要懒惰匹配 :
<[Bb]>.*?</[Bb]> 会匹配到两个<b>text1</b> <b>text2</b>
| 贪婪版 | 懒惰版 |
|---|---|
| * | *? |
| + | +? |
| {n,} | {n,}? |
位置匹配
单词边界(boundary)
\b:匹配单词的开始或者结束位置,也就是单词边界:单词和符号之间的边界
单词可以是中文字符,英文字符,数字
符号可以是中文符号,英文符号,空格,制表符,换行
具体来说:\b匹配的位置是这样的位置,这个位置位于一个能够用来构成单词的字符(\w)和一个不能用来构成单词的字符(\W)之间
例子:
\bcat\b 可以匹配到 the cat catcat 中的第一个cat,因为它前面与后面都有一个单词,因此存在单词分隔符,而不会匹配到后面的catcat
这里有个一开始看不懂的例子:
# 为什么cat匹配不到,因为cat是单词,它前面与后面都有一个单词,因此存在单词分隔符
>>> re.findall(r"\Bcat\B","the cat cao")
[]
# -却能匹配到,因为-不是单词,所以尽管它前后都有单词,但与-之间不存在单词分割符(除了-,其他\W也是一样的)
>>> re.findall(r"\B-\B","color - code")
['-']
注意:java与python中有个地方不同,一个匹配失败,一个成功
String str = " 2 ";
String rex = "\b2\b";
Pattern pattern = Pattern.compile(rex);
Matcher matcher = pattern.matcher(str);
if (matcher.matches())
System.out.println("匹配成功");
else
System.out.println("匹配不成功"); // 这是结果
>>> s=" 2 "
>>> m=re.search(r'\b2\b',s)
>>> m
<_sre.SRE_Match object; span=(1, 2), match='2'>
字符串边界
| 符号 | 用途 |
|---|---|
| ^ | 默认模式下:匹配整个字符串开始位置;在多行模式下:可以匹配换行符后的开始位置 |
| $ | 默认模式下:匹配整个字符串结束位置;在多行模式下:可以匹配换行符后的结束位置 |
子表达式(分组)
用()将正则表达式括起来的就是子表达式,子表达式可以嵌套
例子:
年份
19|20\d{2} 错误,这会匹配19或者20xx
(19|20)\d{2} 正确
IP
* 任意的1位或2位数字
* 任意的以1开头的3位数字
* 任意的以2开头,0-4为第二位的3位数字
* 以25开头,第3位数字是0-5的3位数字
如下,实现了匹配上面的合法的0-255之间的数字
(\d{1,2}) | (1\d{2}) | (2[0-4]\d) | (25[0-5])
因此匹配IP的正则如下:
(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.){3} ((\d{1,2})|(1\d{2})|(2[0-4]\d) |(25[0-5]))
子表达式嵌套
使用的是深度优先搜索,以下面的例子来解释:
- group(0)代表整个正则表达式
- group(1)代表第1个子表达式,也就是最外层的括号
- group(2)代表第2个子表达式
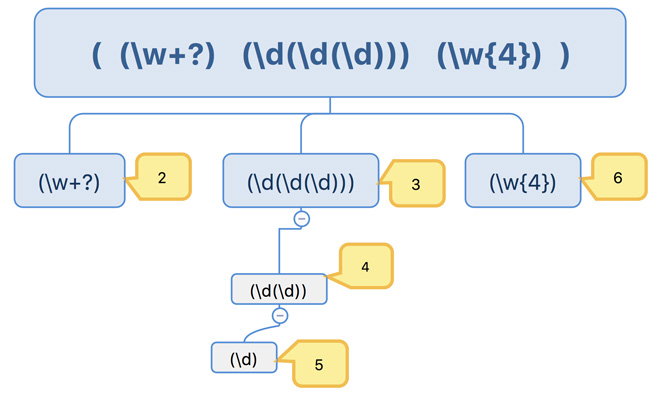
>>> s="jizx333hhhh"
>>> m=re.search(r"((\w+?)(\d(\d(\d)))(\w{4}))",s)
>>> m.group(0)
'jizx333hhhh'
>>> m.group(1) # 上图中的根节点
'jizx333hhhh'
>>> m.group(2)
'jizx'
>>> m.group(3)
'333'
>>> m.group(4)
'33'
>>> m.group(5)
'3'
>>> m.group(6)
'hhhh'
>>> m.group(7)
IndexError: no such group
不保存分组?:
(:X)在正则中表示所匹配的子组X不作为结果输出,称为非捕获分组,不想被捕获的时候使用,可以提高程序执行速度
正常情况(X)中的X会被作为新增的一个组序号输出,比如(A)(B),A的序号1,B的序号2
如果(?:A)(B),A将没有序号不输出,B的序号为1
import re
text="我的电话是1234567890"
pat1=r"(\d{3})(\d{3})(\d{4})"
pat2=r"(?:\d{3})(\d{3})(\d{4})"
match=re.search(pat1,s)
print(match.groups())
match=re.search(pat2,s)
print(match.groups())
# ('123', '456', '7890')
# ('456', '7890')
python中的一个坑
python中split方法,在匹配部分加上括号 ()之后所切出的结果是不同的,匹配模式加括号表示保留匹配到的分隔子串
import re
res=re.split("\|" , ' runoob|runoob|runoob.')
# [' runoob', 'runoob', 'runoob.']
res=re.split("(\|)" , ' runoob|runoob|runoob.') # 添加括号,会保留分割符
# [' runoob', '|', 'runoob', '|', 'runoob.']
如果你不想保留分割字符串到结果列表中去,但仍然需要使用到括号来分组正则表达式的话, 确保你的分组是非捕获分组,形如 (?:pattern)
回溯引用
回溯引用指的是模式的后半部分引用在前半部分中定义的子表达式。
\0表示整个正则表达式、\1表示第一个子表达式、\2表示第二个子表达式,以此类推
this is is a apple,and and I like it it.
[ ]+(\w+)[ ]+\1 匹配重复出现两次的单词,\1表示的就是(\w+)
子表达式(分组)命名
除了使用上面\1 、\2的方式,来引用子表达式,还可以为子表达式命名,然后引用。
为子表达式命名:(?P<name> rexp)
引用子表达式:(?P=name)
例子:
匹配单、双引号包围的字符串
文本:
she said: "I love you",and he replied 'me,too'
正则表达式:(?P<quote>['"]).*?(?P=quote) 等价于(['"]).*?\1
结果:
she said: “I love you”,and he replied ‘me,too’
使用回溯替换
将电话格式进行修改:
文本:
我的电话是1234567890
搜索表达式:
(\d{3})(\d{3})(\d{4})
替换表达式:
\1***\2
结果:
我的电话是123***7890
Javascript 在搜索表达式中使用\1,在替换表达式中使用$1来获取引用
使用回溯进行大小写
不过支持该用法的不多(java不支持)
\E end,表示大小写转换的结束范围
\l low,表示把下一个字符转为小写
\L Low,表示把\L与\E之间的字符转为小写
\u up,表示把下一个字符转为大写
\U Up,表示把\U与\E之间的字符转为大写
举例:
搜索正则表达式<([Hh][1-6])>(.*?)</\1>
替换正则表达式<$1>\U$2\E<$1>
注意:字母有大小写之分,文字没有。
前后查找
向前查找、向后查找实际上都是子表达式。它们查找满足条件的字符串,但忽略掉其中指定的部分(不消费)。
具体理解是:从字符串开始位置,有一个光标,光标每向前移动一次,就在光标所在的位置之前或之后判断某些字母是否符合条件,如果符合,就把光标所在位置之前的字符串返回,但忽略子表达式匹配到的字符串
区别是:
- 向前查找:真正需要的是前面部分的字符串( http: )。
- 向后查找:真正需要的是后面部分的字符串( $400 )。
- 向前查找模式的长度是可变的,可以包含.和+之类的元字符
- 向后查找模式只能是固定长度的。(个人理解为:如果不是固定长度的话,可能会把后面需要输出的部分给隐藏起来)
正向向前查找(大部分语言支持)
(?=需要匹配但不在结果中的正则表达式)
向前查找指定了一个必须匹配但不在结果中返回的模式,正向是指等于,负向指不等于,后面会讲。
例子1:

例子2:
文本:
http://www.baidu.com
https://www.baidu.com
ftp://ftp.forta.com
正则表达式:
.+(?=:) 需要匹配到冒号,但在结果中不需要该冒号
结果:
http
https
ftp
正向向后查找
(?<=需要匹配但不在结果中的正则表达式)
例子1:

例子2:
文本:
AAA:$23.45
BBB:$567.45
total items found:2
正则表达式:
(?<=\$)[0-9.]+ 需要匹配到美元$,但在结果中不需要$
结果:
23.45
567.45
向前向后结合
目标:提取出\
文本:
<head>
<title> ben forta's homepage </title>
</head>
正则表达式:
(?<=\<title\>).*(?=\</title\>)
结果:
ben forta's homepage
负向前后查找(对前后查找取非)
前面介绍的用法称为 正向前查找 和 正向后查找 ,“正”指的是寻找匹配的事实
前后查找还有一种不太常见的用法:负前后查找,“负”指的是寻找不相匹配的事实
- 负向前查找:将向前查找 不与给定模式相匹配的文本
- 负向后查找:将向后查找 不与给定模式相匹配的文本
使用!在进行取非
| 操作法 | 说明 |
|---|---|
| (?=) | 正向前查找 |
| (?!) | 负向前查找 |
| (?<=) | 正向后查找 |
| (?<!) | 负向后查找 |
例子:
查找价格
文本:
I paid $30 for 100 apples, 50 oranges ,and 60 pears. I saved $5 on this order.
正则表达式:(?<=\$)\d+
结果:
I paid \$30 for 100 apples, 50 oranges ,and 60 pears. I saved $5 on this order.
查找数量
文本:
I paid $30 for 100 apples, 50 oranges ,and 60 pears. I saved $5 on this order.
正则表达式:\b(?<!\$)\d+
结果:
I paid \$30 for 100 apples, 50 oranges ,and 60 pears. I saved $5 on this order.
注意到这里有个\b,为什么要这样呢?看下面的结果就知道了
正则表达式:
(?<!\$)\d+结果:
I paid \$30 for 100 apples, 50 oranges ,and 60 pears. I saved $5 on this order.
$30中的0也被匹配上了。因为0前面的3不是\$,完全符合
(?<!\$)\d+
嵌入条件
并非所有正则表达式实现都支持条件处理
正则表达式里的条件要用(?(condition)true_regx|false_regx)来定义,可以没有false_regx。
之前见过几种非常特殊的条件了:
.?、[]?或()?匹配前一个字符或者表达式(?=……)和(?<=……)匹配前面或后面的文本
回溯引用条件
(?(回溯引用的id)true-regx|false-regx) ,当回溯引用存在时,匹配true-regx模式,否则匹配false-regx,
例子:匹配合法的电话
文本:
123-456-7890
(123)456-7890
(123)-456-7890
(123-456-7890
1234567890
123 456 7890
正则表达式:
(\()? \d{3} (?(1)\)|-) \d{3}-\d{4}
结果:
123-456-7890
(123)456-7890
(123)-456-7890
(123-456-7890
1234567890
123 456 7890
其中(?(1)\)|-)就是回溯引用条件,?(1)表示子表达式1存在时,进行匹配右括号),否则匹配连字符-
前后查找条件
(?(向前向后查找表达式)true-regx|false-regx)
在实际工作中,该方法相当少见,因为有更简单的方法来到达同样的目的。
例子:
文本:
11111
22222
33333-
44444-4444
正则表达式:\d{5}(?(?=-)-\d{4})
结果:
11111
22222
33333-
44444-4444
(?(?=-)-\d{4}) 中用(?=-)来进行向前匹配,如果条件成立,则-\d{4}将匹配连字符和随后的4位数字,这样33333- 将被排除在外。
总结
元字符可以分为2类:
- 一种是本身就是元字符,转义后变为普通字符,比如
^ $ *,用\进行转义恢复成普通字符 - 另一种是需要\进行配合,才表示元字符,否则就是普通的字符,比如
\w \s \d